FE507 – Seeing Theory
Basic Probability
An introduction to the basic concepts of probability theory.
Chance Events
Randomness is all around us. Probability theory is the mathematical framework that allows us to analyze chance events in a logically sound manner. The probability of an event is a number indicating how likely that event will occur. This number is always between 0 and 1, where 0 indicates impossibility and 1 indicates certainty.
A classic example of a probabilistic experiment is a fair coin toss, in which the two possible outcomes are heads or tails. In this case, the probability of flipping a head or a tail is 1/2. In an actual series of coin tosses, we may get more or less than exactly 50% heads. But as the number of flips increases, the long-run frequency of heads is bound to get closer and closer to 50%.
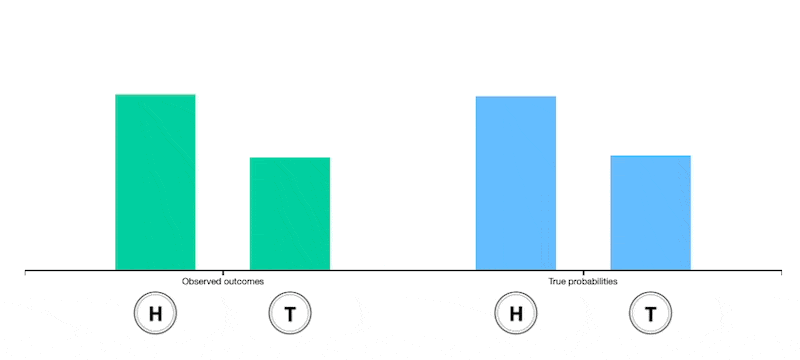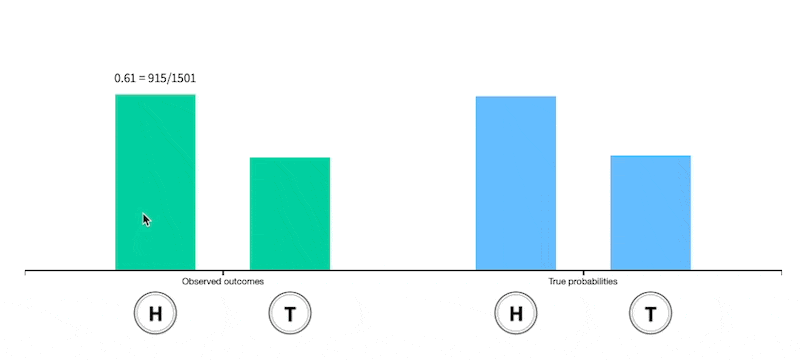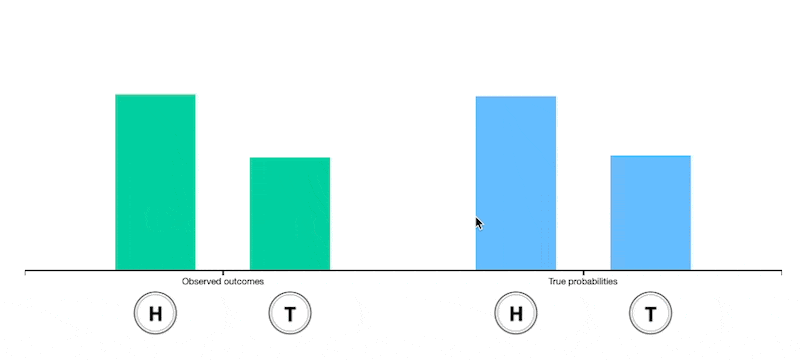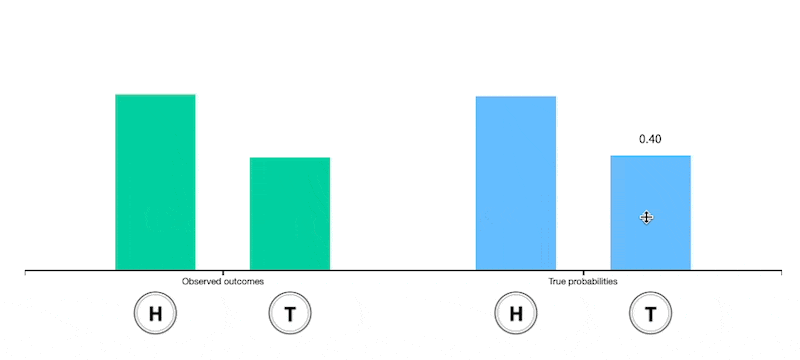
Unfair coin
Expectation
The expectation of a random variable is a number that attempts to capture the center of that random variable's distribution.
It can be interpreted as the long-run average of many independent samples from the given distribution.
More precisely, it is defined as the probability-weighted sum of all possible values in the random variable's support,
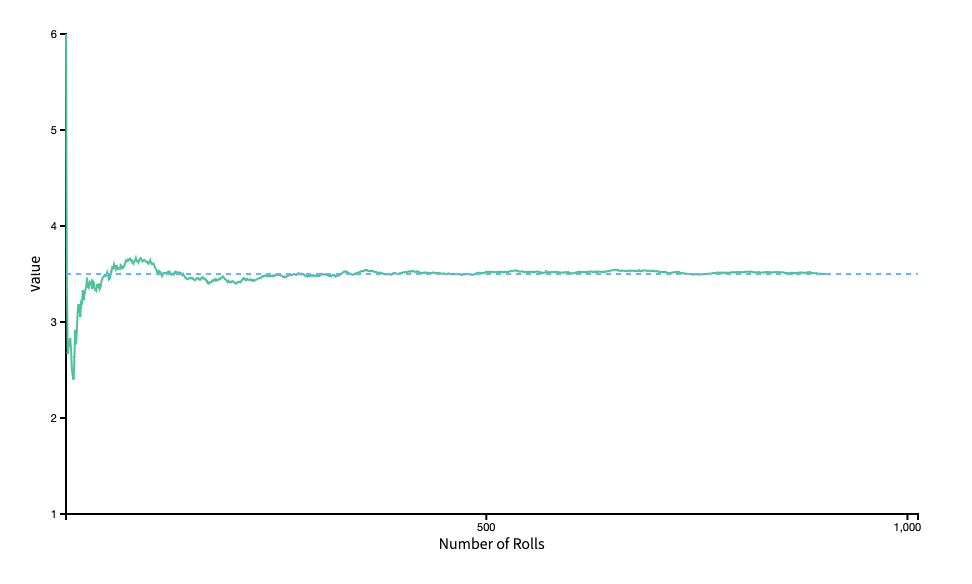
Consider the probabilistic experiment of rolling a fair die and watch as the running sample mean converges to the expectation of 3.5.
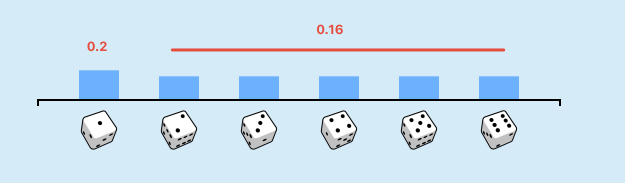
Notice: Currrently, this is a fair die and probability for all number being got is
unfair dir
Change the distribution of the different faces of the die (thus making the die biased or "unfair") and observe how this changes the expectation.
Variance
Whereas expectation provides a measure of centrality, the variance of a random variable quantifies the spread of that random variable's distribution. The variance is the average value of the squared difference between the random variable and its expectation,
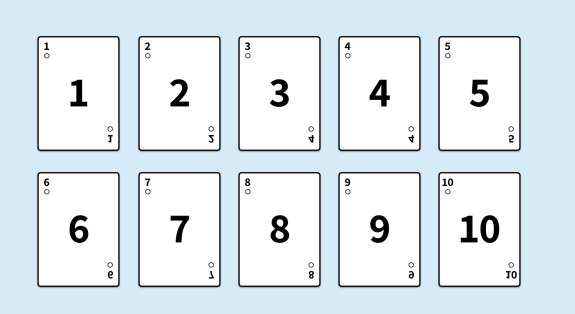
Draw cards randomly from a deck of ten cards. As you continue drawing cards, observe that the running average of squared differences (in green) begins to resemble the true variance (in blue).
| Card Number | abs(X-E[X]) | (X-E[X])^2 | P(X) |
|---|---|---|---|
| 1 | 4.5 | 20.25 | 1/10 = 0.1 |
| 2 | 3.5 | 12.25 | 0.1 |
| 3 | 2.5 | 6.25 | 0.1 |
| 4 | 1.5 | 2.25 | 0.1 |
| 5 | 0.5 | 0.25 | 0.1 |
| 6 | 0.5 | 0.25 | 0.1 |
| 7 | 1.5 | 2.25 | 0.1 |
| 8 | 2.5 | 6.25 | 0.1 |
| 9 | 3.5 | 12.25 | 0.1 |
| 10 | 4.5 | 20.25 | 0.1 |
Compound Probability
This chapter discusses further concepts that lie at the core of probability theory.
Set Theory
A set, broadly defined, is a collection of objects. In the context of probability theory, we use set notation to specify compound events. For example, we can represent the event "roll an even number" by the set {2, 4, 6}. For this reason it is important to be familiar with the algebra of sets.





Counting
It can be surprisingly difficult to count the number of sequences or sets satisfying certain conditions. For example, consider a bag of marbles in which each marble is a different color. If we draw marbles one at a time from the bag without replacement, how many different ordered sequences (permutations) of the marbles are possible? How many different unordered sets (combinations)?
Permutation :
Combination:
1 marbel

Permutation:

Combination:

2 marbels

Permutation:

Combination:

3 marbles

Permutation:

Combination:

4 marbles

Permutation (24)


Combination


Conditional Probability
Conditional probabilities allow us to account for information we have about our system of interest. For example, we might expect the probability that it will rain tomorrow (in general) to be smaller than the probability it will rain tomorrow given that it is cloudy today. This latter probability is a conditional probability, since it accounts for relevant information that we possess.
Mathematically, computing a conditional probability amounts to shrinking our sample space to a particular event. So in our rain example, instead of looking at how often it rains on any day in general, we "pretend" that our sample space consists of only those days for which the previous day was cloudy. We then determine how many of those days were rainy.
Click on the tabs below to visualize the shrinking of the sample space.




Probability Distributions
A probability distribution specifies the relative likelihoods of all possible outcomes.
Random Variable
Formally, a random variable is a function that assigns a real number to each outcome in the probability space. Define your own discrete random variable for the uniform probability space on the right and sample to find the empirical distribution.

Sample from probability space to generate the empirical distribution of your random variable.

Discrete and Continues
There are two major classes of probability distributions:
- Descrite
- Continuous
Discrete
A discrete random variable has a finite or countable number of possible values.

Choose one of the following major discrete distributions to visualize. The probability mass function f(x) is shown in yellow and the cumulative distribution function F(x) in orange (controlled by the slider).
Bernoulli
A Bernoulli random variable takes the value 1 with probability of pp and the value 0 with probability of 1−p1−p. It is frequently used to represent binary experiments, such as a coin toss.


Binomial
A binomial random variable is the sum of nn independent Bernoulli random variables with parameter pp. It is frequently used to model the number of successes in a specified number of identical binary experiments, such as the number of heads in five coin tosses.


Geometric
A geometric random variable counts the number of trials that are required to observe a single success, where each trial is independent and has success probability p. For example, this distribution can be used to model the number of times a die must be rolled in order for a six to be observed.


Poisson
A Poisson random variable counts the number of events occurring in a fixed interval of time or space, given that these events occur with an average rate λλ. This distribution has been used to model events such as meteor showers and goals in a soccer match.


Negative Binomial
A negative binomial random variable counts the number of successes in a sequence of independent Bernoulli trials with parameter pp before rr failures occur. For example, this distribution could be used to model the number of heads that are flipped before three tails are observed in a sequence of coin tosses.


Continuous
A continuous random variable takes on an uncountably infinite number of possible values (e.g. all real numbers).
If X is a continuous random variable, then there exists unique nonnegative functions, f(x) and F(x), such that the following are true:

Uniform
The uniform distribution is a continuous distribution such that all intervals of equal length on the distribution's support have equal probability. For example, this distribution might be used to model people's full birth dates, where it is assumed that all times in the calendar year are equally likely.


Normal
The normal (or Gaussian) distribution has a bell-shaped density function and is used in the sciences to represent real-valued random variables that are assumed to be additively produced by many small effects. For example the normal distribution is used to model people's height, since height can be assumed to be the result of many small genetic and evironmental factors.


Student T
Student's t-distribution, or simply the t-distribution, arises when estimating the mean of a normally distributed population in situations where the sample size is small and population standard deviation is unknown.


Chi Squared
A chi-squared random variable with kk degrees of freedom is the sum of kkindependent and identically distributed squared standard normal random variables. It is often used in hypothesis testing and in the construction of confidence intervals.


Central Limit Theorem