FE581 – 0522 - Logistic Regression and Clusstering Methods
FE581 – 0522 - Logistic Regression and Clusstering Methods4.3 Logistic Regression4.3.1 The Logistic Model4.3.2 Estimating the regression Coefficients4.3.3 Making Predictions4.4.4 multiple logistic regression 10.3 Clustering Methods10.3.1 K-Means Clustering10.3.2 Hierarchical Clustering
4.3 Logistic Regression
library(ISLR2)df <- Defaulthead(df)default student balance income1 No No 729.5265 44361.6252 No Yes 817.1804 12106.1353 No No 1073.5492 31767.1394 No No 529.2506 35704.4945 No No 785.6559 38463.4966 No Yes 919.5885 7491.559
str(df)'data.frame': 10000 obs. of 4 variables:$ default: Factor w/ 2 levels "No","Yes": 1 1 1 1 1 1 1 1 1 1 ...$ student: Factor w/ 2 levels "No","Yes": 1 2 1 1 1 2 1 2 1 1 ...$ balance: num 730 817 1074 529 786 ...$ income : num 44362 12106 31767 35704 38463 ...
In the default data set
| x1 - student | x2 - balance | x3 - income | Y |
|---|---|---|---|
| yes / no | num | num | yes/no |
Rather than modeling this response Y directly, logistic regression models the probability that Y belongs to a particular category.
Because we want to estimate the probability of Y belongs to one of the particular category, that means the result of our estimation must fall into the range of [0,1]. but if we use normal linear regression, it wont able to achieve this. As in linear regression, the line can have any value even less than zero and bigger than one.
That is why we need logistic regression , where it can be written as:
4.3.1 The Logistic Model
Question: How should we model the relationship between
If we use linear regression to represent this, then it will be:
In logistic regression, the logistic function or the sigma function is used:
in our case,
So we can rewrite the logistic function as:
for Example:
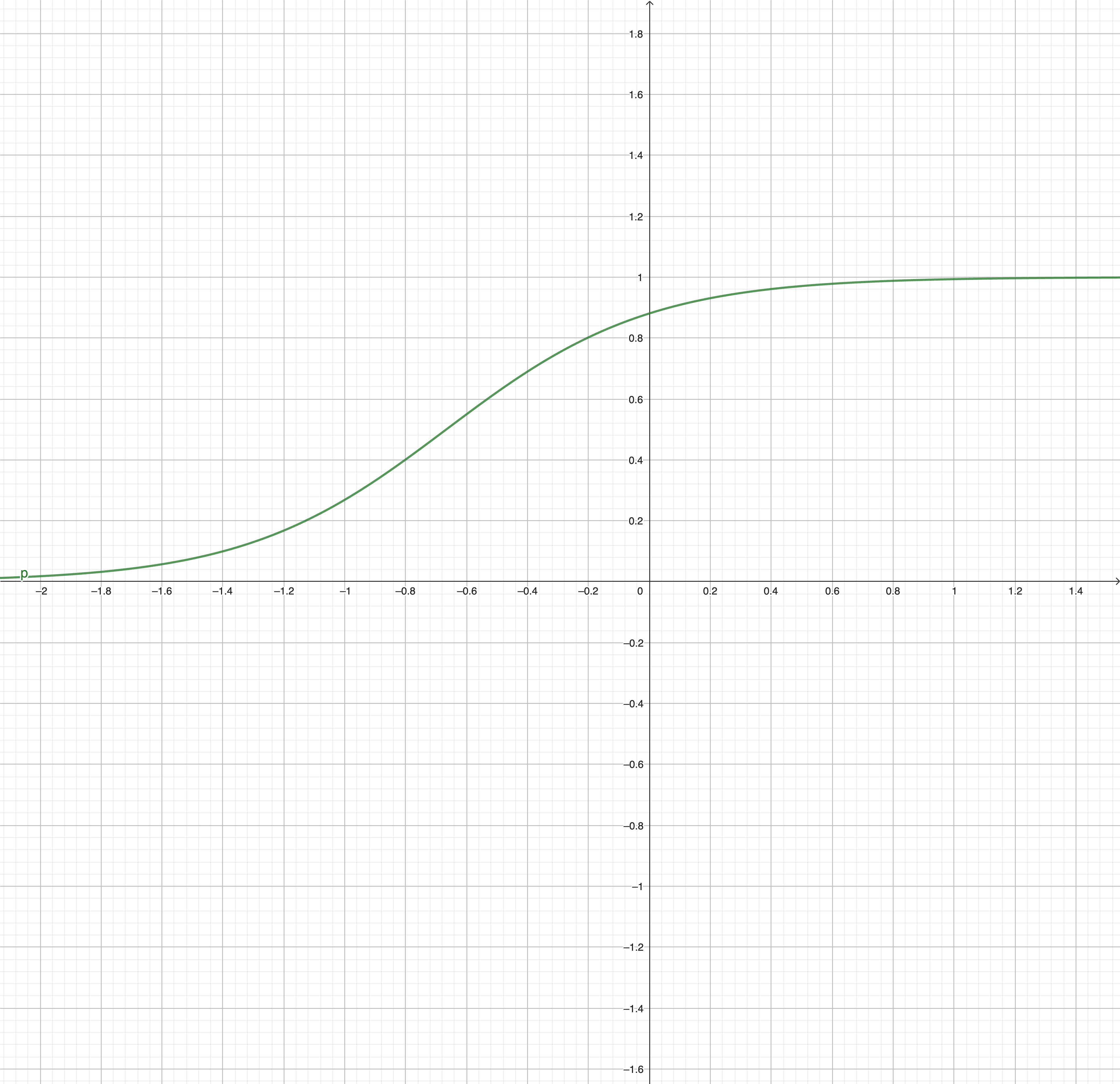
Then we can find that no matter what is the value of
Now we have the function that satisfies our requirements for the output ( should be range between 0 and 1), our next job is to find the values of
We can rewrite the function in (4.2) in a slightly different way:
so we can achieve:
where the LHS:
Odds basically means success ratio, such as one success out of five means we have
By taking logarithm on (4.3) we can further make changes as:
the LHS is called as logit or log-odds, and we can easily realize that, the relationship between X and p(X) are not linear.
4.3.2 Estimating the regression Coefficients
As we talked earlier, we need to find
The process of finding
From the formula we can say the actually what maximum likelihood dose is it is trying to maximize the probability of binomial success outcome.
By using some programming languages like R or Python or maybe Excel (lol it is not a programming language) we can get the estimated values of the (4.3) or (4.2), which are the coefficients of the logistic function.
And statistically we will get the resulting table:
| - | Coefficients | Std. error | Z-statistics | p-value |
|---|---|---|---|---|
| Intercept | -10.6513 | 0.3612 | -29.5 | 0.000230045 |
| balance | 0.0055 | 0.0002 | 24.9 | 0.00001452 |
| which results the following logistic regression model : |
4.3.3 Making Predictions
It is as easy as putting the values back into our function. if x is a quantitative variable (numerical) we just simply put x back into the formula of (4.2) or (4.3). If x is a qualitative variable (categorical) we use dummy variable that takes the value of 1 or 0, then put it back to the formula.
4.4.4 multiple logistic regression
In multiple x case, the formula for slightly changes into:
10.3 Clustering Methods
Clustering is an unsupervised learning method, which aims to find relationships between either:
observations on the different row (grouping)
variables on the different column (reasoning)
Simply, it is a method to put similar things together.
So one of the most important things to consider in clustering methods is how we define things (observations) are similar
10.3.1 K-Means Clustering

Algorithm:
We have n data observations as
Randomly assign each observation point to a cluster
Compute the centroid (mean) of each cluster
Calculate the Euclidian distance between each class centroid
Reassign the observation
repeat 1-4 until we get a minimal total within class variation(mean of Euclidian distances) or SSE (Sum of Squared Error ,calculated as total Euclidian distances).
Calculation Example:


10.3.2 Hierarchical Clustering
One potential disadvantages of K-means is that we need to first define the # of clusters.
Main tasks in hierarchical clustering includes:
How to draw the dendrogram
How to cut the dendrogram (where to cut)
How to evaluate the model
To build a dendrogram (bottom to top approach):
Calculate the dissimilarities between each observations. (to build up from the bottom)
Manhattan Distance (
Euclidian Distance Squared (
Euclidian Distance (
Pick the minimum distance and fuse.
Calculate the linkage between groups of observations. (to build up further branches)
complete
average
single
centroid
Pick the minimum linkage and fuse.
repeat 1-4 until we reach the root of the dendrogram.
When calculating the linkage, there are 4 different methods as given above, and we have different calculation approach, let's assume in some time, we end up with two cluster sets as
Single Linkage: Find the minimum distance between any point in the first set to any point in the second set. That is, find the minimum among the distances d(x1,x4), d(x1,x5), d(x2,x4), and d(x2,x5). This minimum distance is the single linkage distance.
Complete Linkage: Find the maximum distance between any point in the first set to any point in the second set. That is, find the maximum among the distances d(x1,x4), d(x1,x5), d(x2,x4), and d(x2,x5). This maximum distance is the complete linkage distance.
Average Linkage: Calculate the average of all the distances between points in the first set to points in the second set. That is, calculate the average of the distances d(x1,x4), d(x1,x5), d(x2,x4), and d(x2,x5). This average distance is the average linkage distance.
Centroid Linkage: Calculate the centroids of the two sets first. The centroid of a set is the point whose coordinates are the average of the coordinates of all the points in the set. Let c1 be the centroid of {x1,x2} and c2 be the centroid of {x4,x5}. Then, calculate the distance between these two centroids, d(c1,c2). This distance is the centroid linkage distance.